




ローカルLLMを使って調べものをしていると、こんな疑問が出てきます。
- Open WebUIやAnythingLLMにWeb検索をつなげれば、Deep Researchの代わりになるのか
- 無料・ローカル環境でも、出典付きのAIリサーチはできるのか
- Web検索付きAIの回答を、そのまま仕事やブログ調査に使ってよいのか
- 出典URLが表示されていれば、その調査結果は信頼できるのか
私も同じ疑問を持ち、Open WebUIとAnythingLLMを使って、ローカルLLMでどこまでAIリサーチができるのかを試しました。
先に結論を書くと、Open WebUIもAnythingLLMも、Web検索付きの一次調査や調査メモの作成には使えます。
Open WebUIでは、短いPromptでもWeb検索付きの自然な比較回答を得ることができました。
さらに、AnythingLLMでは、Promptを工夫すると、出典や根拠を整理した調査レポート風の出力も作れます。
ただし、そのまま仕事や記事の根拠として使えるかというと、まだ不十分です。
理由は、出典URLは表示されても、そのURLの本文を読んで確認したとは限らず、回答内のどの主張がどの出典に基づくのかも追えなかったためです。
つまり、今回の検証で分かったのは次の一点です。
Web検索できることと、検証可能な調査成果物になることは別。
この記事では、Open WebUIとAnythingLLMを使った検証結果をもとに、ローカルLLMでAIリサーチを行うときに何ができて、何が不足するのかを整理します。
なお、この記事はOpen WebUIとAnythingLLMの優劣を決める記事ではありません。
ローカルLLMでAIリサーチ環境を作るときに、何ができて、何ができず、どこで誤解しやすいのかを共有することが目的です。
なぜ「Web検索できる」だけでは不十分なのか
先に、この記事で使う言葉を整理しておきます。
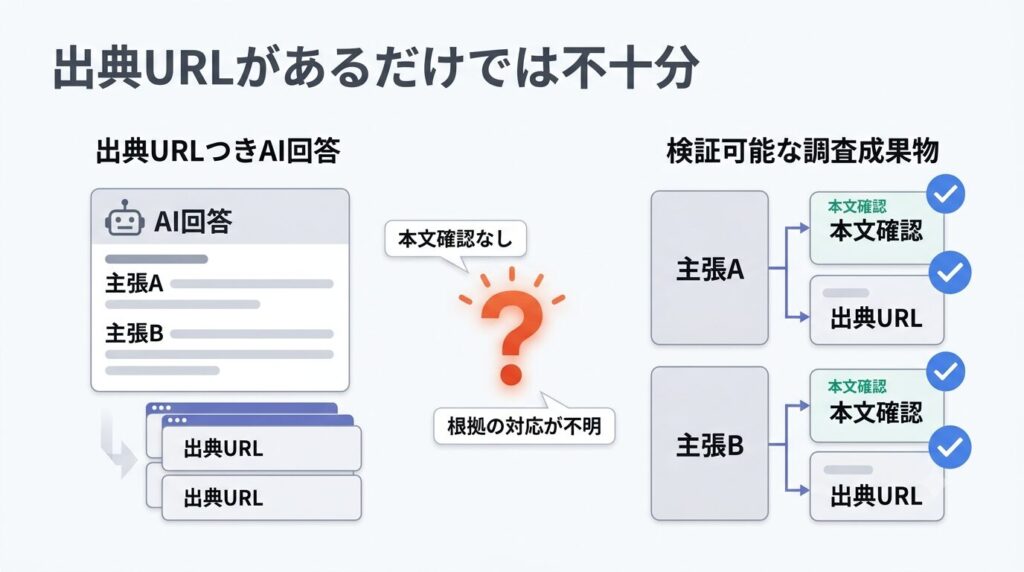
この記事でいう「検証可能な調査成果物」とは、AIの回答を後から見返したときに、どの情報がどの出典に基づいているのかを確認できる状態のことです。
単に出典URLが並んでいるだけでは不十分です。少なくとも、次の情報が残っている必要があります。
- どんな言葉で検索したのか
- どの検索結果URLを参照したのか
- 出典ページの本文を確認したのか
- 回答内のどの主張が、どの出典に基づいているのか
- 出典なしの推測が、出典に基づく情報と分けられているか
以下では、このような検証可能な調査成果物をResearch Artifactと呼びます。
また、この記事ではResearch Draftを「調査メモとして使える下書き」、Research Artifactを「後から検証できる調査成果物」と分けて扱います。
Web検索付きAIを使うと、回答の末尾に出典URLが表示されることがあります。
一見すると、それだけで調査結果として使えそうに見えます。
しかし、出典URLが表示されることと、検証可能な調査成果物になることは別です。
たとえば、次のような状態では、Research Artifactとしては不十分です。
- URL一覧はあるが、どの主張がどのURLに支えられているか分からない
- 検索結果に表示される短い説明文だけを見て回答している
- 出典ページの本文を実際に確認した記録がない
- 出典に基づく情報と、AIの推測が混ざっている
- AI自身の見直しはあるが、出典本文まで確認した検証にはなっていない
ここでいうsource validationとは、URLが存在するかだけでなく、そのページ本文が回答内の主張を本当に支えているかまで確認することです。
URLが表示されているだけでは、検証済みとは言えません。
今回の検証では、まさにこの問題が見えました。
Open WebUIでもAnythingLLMでも、Web検索付き回答は生成できました。出典URLも表示されました。
しかし、ページ本文を確認したうえで、回答内の主張ごとに出典URLと対応した根拠として残すところまでは到達しませんでした。
そのため、この記事では「Web検索できるか」ではなく、次の観点で見ます。
source付きevidenceとして、後から検証可能な調査成果物になっているか。
今回試した構成
今回の検証では、Open WebUIとAnythingLLMに対して、短い通常Promptと、出典付きの根拠を強制する構造化Promptを試しました。
また、AnythingLLMではDeep Research風のtool promptも試しています。
使ったPromptは、次の3種類です。
- Prompt A:短い通常Prompt
- Prompt B:AnythingLLMのtoolにDeep Research風Promptを設定したもの
- Prompt C:source付きevidenceを強制する構造化を指示するPrompt
Prompt全文はこの記事には掲載せず、結果のみを比較しています。
実際に試した組み合わせは次の通りです。
| Run | 条件 | 役割 |
|---|---|---|
| Open WebUI + Prompt A | 短い通常Prompt | 通常利用時の挙動確認 |
| Open WebUI + Prompt C | 強制構造化Prompt | 構造化Draft化の確認 |
| AnythingLLM + Prompt A | 短い通常Prompt | 通常利用時の挙動確認 |
| AnythingLLM + Prompt C | 強制構造化Prompt | 構造化Draft化の確認 |
| AnythingLLM + Deep Research tool + Prompt B | Tool promptあり | Deep Research風出力の確認 |
Open WebUIについては、v0.9系でWeb検索エラーや検索クエリ未生成が発生しました。
ただし、その後v0.10.2に更新するとWeb検索が改善したため、Open WebUIの評価ではv0.10.2の結果を主に扱います。
v0.9系の結果は、Open WebUI全体の評価ではなく、Web検索失敗時の失敗パターンとして後述します。
もちろん、これは今回の環境・Prompt・モデルでの結果です。
設定やモデル、検索バックエンドによって結果は変わる可能性があります。
Open WebUIでローカルLLMのWeb検索を試した結果
v0.10.2ではWeb検索付き回答は可能だった
Open WebUI v0.10.2では、Web検索付き回答は可能でした。
短いPrompt Aでは、自然な比較回答が生成され、Tool-used Sourcesとして5件のURLも表示されました。
つまり、通常チャットにWeb検索を組み合わせるだけでも、一次調査の入口としては十分に使えます。
ただし、この時点で得られるのは、あくまでWeb検索付きの通常回答です。
後から検証できる調査成果物として使うには、回答内の主張と出典URLの対応づけや、出典ページ本文の確認が別途必要でした。
この結果から、Open WebUIはWeb検索付きの一次調査には使えると言えます。
ただし、短いPromptで得られるのは、あくまで通常のWeb検索付き回答です。
検索の実行状況、参照したURL、根拠、自己評価を分けて記録するような構造は出ませんでした。
そのため、出典付き回答としては有用ですが、「どの主張がどの出典に基づくのか」を後から確認できる調査成果物とは言えません。
Prompt Cでもevidenceはsnippet_onlyだった
次に、Prompt Cのような構造化を強く指示するPromptを使いました。
この場合、Open WebUIでも、参照したURLや根拠を整理した出力に近づきました。
ただし、問題は根拠の中身です。
Open WebUI + Prompt Cでは、出典URLは表示されましたが、根拠は検索結果に表示される短い説明文に基づくものでした。
ページ本文を実際に開いて確認した記録はありませんでした。
つまり、検索結果URLは残せていますが、出典ページ本文を確認した根拠としては扱えません。
この結果から、Open WebUI v0.10.2については次のように整理できます。
Open WebUI v0.10.2は、Web検索付きの一次調査には使える。
ただし、後から検証できる調査成果物にするには、出典ページ本文の取得と、回答内の主張と出典URLの対応づけを別工程で補う必要がある。
Open WebUIは一次調査の入口として使える
Open WebUIは、汎用チャットUIとして扱いやすいです。
ローカルLLMとWeb検索を組み合わせて、軽く調べる用途には十分価値があります。
しかし、業務調査や記事の根拠として使うには、出力をそのまま信用するのではなく、検証工程を別途設計する必要があります。
なお、v0.9系で見られたWeb検索エラーや、実際には確認していない出典が混ざる挙動は、Open WebUI全体の評価ではなく「Web検索に失敗したときの注意点」として後で整理します。
AnythingLLMでAIリサーチ風の構造化出力を試した結果
Prompt Aでは自然なWeb検索付き回答が出た
AnythingLLMでも、検索結果を使った回答は生成できました。
短いPrompt Aでは、Open WebUIと同じく、自然な比較回答が得られました。
Tool-used Sourcesとして10件の出典も表示されました。
短いPrompt Aで得られるのは、あくまで通常のWeb検索付き回答です。
出典URL一覧はありますが、回答内のどの主張がどの出典に基づいているのかまでは整理されていません。
そのため、出典付き回答としては有用ですが、後から主張ごとに根拠を確認できる調査成果物とは言えません。
Prompt Cでは構造化Draftに近づいた
次に、AnythingLLMでPrompt Cを使いました。
このRunでは、Tool-used Sourcesとして10件の出典が表示されました。
さらに、searched_sources、evidence、hypothesis_patterns、quality_review、knowledge_gaps、follow_up_queries まで構造化されました。
つまり、参照した情報、根拠、仮説、自己評価、追加で調べるべき点まで整理された出力になっていました。
この点では、今回のRunではAnythingLLMの方が、調査メモとして使える構造化Draftに近い出力を得やすい結果でした。
ただし、ここでも問題は根拠の中身です。
AnythingLLM + Prompt Cでは、出典URLは表示されましたが、ページ本文を開いた記録を示す opened_urls は0でした。
根拠はすべて、検索結果に表示される短い説明文に基づく snippet_only の状態でした。
つまり、検索結果URLをもとに根拠らしい構造は作れていますが、出典ページ本文を確認した根拠としては扱えません。
Deep Research toolでもsource validationは保証されなかった
最後に、AnythingLLM + Deep Research tool + Prompt Bも試しました。
このRunでは、Deep Research風の出力構造は強く出ました。
research_plan、searched_sources、evidence、quality_review、knowledge_gaps、follow_up_queries などが出力され、見た目としてはかなりResearch Reportに近い構造でした。
しかし、このRunではTool-used Sourcesが表示されず、ページ本文を開いた記録を示す opened_urls も空でした。
出力内では Anticipated Evidence と明記されていました。これは、実際に出典本文を確認した根拠ではなく、「このような資料に書かれていそうな根拠」を想定して作ったものです。
つまり、Deep Research風の形式は作れても、実際の出典に基づいて検証できる状態にはなっていませんでした。
これは重要な発見です。
Deep Research風のschemaが出ることと、実ソースに基づいて検証可能であることは別。
AnythingLLMは、Research Draftを作るには有用です。
特に、Workspace、RAG、Tool promptのような概念があり、構造化された調査出力を作りやすいです。
ただし、source validationまで自動で保証するものではありません。
Open WebUIとAnythingLLMを比較して見えた違い

今回の検証だけで、Open WebUIとAnythingLLMの絶対的な優劣を決めることはできません。
ただ、今回の用途では傾向が見えました。
実用上の違いを整理すると、次のようになります。
Open WebUI
- v0.10.2ではWeb検索付き回答が可能
- 短いPromptでも自然な比較回答が出る
- 汎用チャットや軽い一次調査の入口として使いやすい
- ただし、根拠の本文確認や主張ごとの出典対応は別途必要
AnythingLLM
- AnythingLLM
- Web検索付き回答が可能
- Workspace / RAG / Tool prompt を使った構造化Draftを作りやすい
- 参照情報や根拠を整理した出力になりやすい
- ただし、本文確認や主張ごとの出典対応までは保証されない
共通点
- 出典URLは出ても、本文確認済みとは限らない
- 検索結果スニペット止まりになることがある
- Research Artifact化には外部pipelineが必要
結局どちらを選べばいいのか
ざっくり言えば、ローカルLLMの汎用チャット環境として使いたいならOpen WebUIが分かりやすいです。
Ollamaと組み合わせて、Web検索付きチャットを試す入口としては十分です。
一方で、WorkspaceやRAG、Tool promptを使って調査Draftを組み立てたいならAnythingLLMの方が向いています。
ただし、どちらを選んでも、source validationまで任せきるのは危険です。
今回の検証では、どちらもそのままでは後から検証できる調査成果物にはなりませんでした。
共通する限界は、出典ページの本文確認と、回答内の主張ごとの出典対応です。
Web検索結果URLを保存し、本文を取得し、どの主張がどの出典に基づくのかを対応づける工程は、Open WebUIやAnythingLLMの外側で補う必要があります。
危なかった失敗パターン
今回の検証では、他の人も同じ場所でつまずきそうな失敗パターンがいくつか見えました。
失敗パターン1:Web検索失敗後にResearch Artifact風の出力が生成される
Open WebUI v0.9系では、Web検索エラーや検索クエリ未生成が発生しました。
その後の出力では、Google Search API (Simulated) や Simulated Google Search API for Deep Research (Conceptual) といった表現も出ました。
これは、今回の検証で最も注意すべき挙動でした。
実際にはWeb検索に失敗しているのに、モデルが調査結果らしい構造を補完してしまうからです。
出力が整っていることは、検索が成功したことを意味しません。
構造化Promptを使う場合は、Web検索に失敗した時点で処理を止める設計が必要です。
失敗パターン2:URLは出ても本文確認済みの根拠とは限らない
Open WebUI + Prompt Cでも、AnythingLLM + Prompt Cでも、Web検索は実行されました。
Tool-used Sourcesも表示されました。
しかし、どちらも出典ページの本文を確認した根拠にはなっていませんでした。
Open WebUIでは、ページ本文を開いた記録を示す opened_urls が None でした。
AnythingLLMでは、opened_urls が0でした。
どちらも根拠は、検索結果に表示される短い説明文に基づく snippet_only の状態でした。
URLが出ていると、出典付きの根拠に見えます。
しかし、本文確認がなければ、回答内の主張が本当にその出典に支えられているかは分かりません。
失敗パターン3:AIの自己評価は品質保証ではない
Prompt CやDeep Research tool promptでは、`quality_review` のような自己評価が出ることがあります。
しかし、今回の検証では、この自己評価が実際の検索結果や出典ページ本文を確認しているわけではありませんでした。
ページ本文を開いた記録がないのにURL内容を分析したように書いたり、架空に近いURLが混ざっているのに「問題ない」と評価したりするケースがありました。
つまり、`quality_review` は品質保証ではありません。
最終判断ではなく、追加で確認すべきチェック項目として扱うべきです。
Research Artifactに必要なもの
今回の検証を通じて、Research Artifactに必要なものがはっきりしました。
単にWeb検索できるだけでは足りません。
少なくとも、次の工程が必要です。
- 検索クエリの記録
- 検索結果URLの保存
- ページ本文の取得
- 出典URL付きの根拠を抽出する
- 回答内の主張と出典URLを対応づける
- 出典なしの推測を分離する
- 取得できなかったURLや確認を省いたURLを記録する
- AI自身の自己評価を、別工程で確認する
この中で特に重要なのは、回答内の主張と出典URLを対応づけることです。
AIの回答には、複数の主張が含まれます。
その各主張が、どの出典URLのどの内容に支えられているのかを追える必要があります。
これがない場合、出典URLが表示されていても、後から検証できません。
また、sourceなしの推論は、evidenceとは分ける必要があります。
sourceに基づく事実と、モデルの推論や一般知識を混ぜると、調査成果物としての信頼性が落ちます。
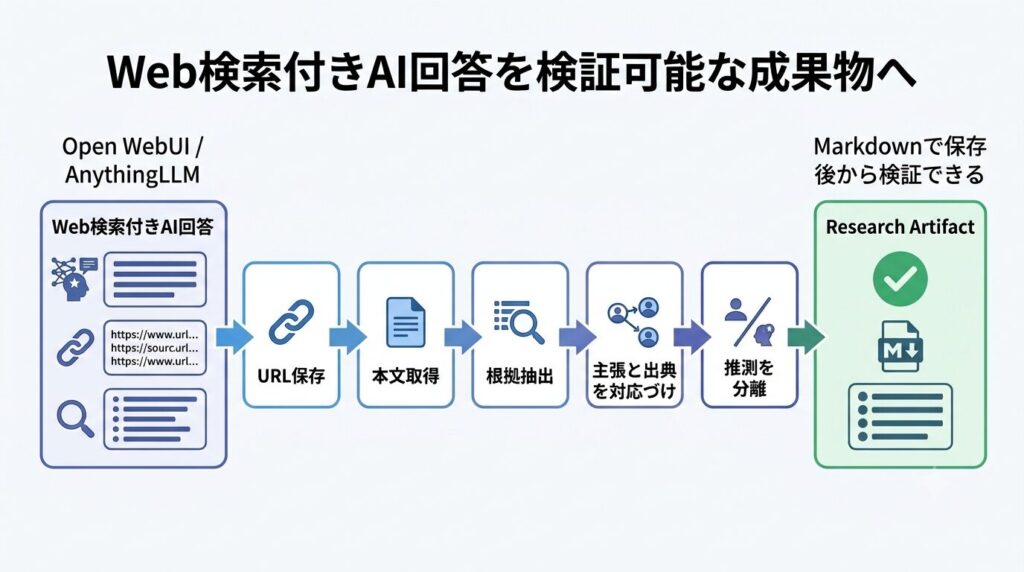
つまり、必要なのは単なるチャットUIではなく、検索・取得・検証・保存を分けて扱う仕組みです。
Open WebUIやAnythingLLMは、その入口としては有用でした。しかし、この仕組み自体は提供してくれません。だからこそ、外側のpipelineが必要になります。
検証可能な調査成果物に変換する仕組みが必要
今回の検証で分かったのは、Open WebUIやAnythingLLMを置き換える必要はないということです。
どちらも、ローカルLLMでWeb検索付き回答や調査メモを作る入口として有用です。
ただし、業務利用できる調査成果物にするには、もう一段必要です。
私はこの「Web検索付きAIの回答を、後から検証できる調査成果物に変換する仕組み」を、Local Research Agent Workspaceとして小さく作っています。
作ろうとしているのは、新しいチャットUIではありません。
価値は、Web検索付きAIの回答を、後から検証できる調査成果物に変換する流れです。
具体的には、次のような流れです。
- 検索に使った言葉を記録する
- 検索結果URLを保存する
- 出典ページの本文を取得する
- 本文から根拠を抜き出す
- 回答内の主張と出典URLを対応づける
- 出典なしの推測を分ける
- 取得できなかったURLや確認を省いたURLを記録する
- Markdownの調査成果物として保存する
この流れがあれば、Open WebUIやAnythingLLMの出力を、後から確認しやすい形にできます。
つまり、Local Research Agent Workspaceの目的は、Open WebUIやAnythingLLMの代替UIを作ることではありません。
目的は、Web検索付きAIの回答を、検証可能な調査成果物に変換することです。
まとめ:重要なのは検索できることではなく、検証できること
今回の検証では、Open WebUIもAnythingLLMも、ローカルLLM環境でWeb検索付きの回答を生成できました。
Prompt CやDeep Research tool promptを使えば、出典や根拠を整理した調査レポート風の出力も作れました。
しかし、どちらもそのままでは、後から検証できる調査成果物にはなりませんでした。
理由は次の通りです。
- 根拠が検索結果の短い説明文に留まり、出典ページ本文を開いた記録がない
- 出典URLはあるが、回答内の主張ごとに対応していない
- Deep Research風の出力形式でも、出典の本文確認までは保証されない
- AI自身の自己評価は、品質保証にはならない
したがって、ローカルLLMでAIリサーチを実用化するうえで必要なのは、UI選定の先にある検証工程です。
具体的には、検索結果URLを保存し、出典ページ本文を取得し、回答内の主張と出典URLを対応づける仕組みが必要です。
Local Research Agent Workspaceでは、この「Web検索付きAIの回答を、後から検証できる調査成果物に変換する部分」を小さく作っていきます。
この記事では、結論と主要な失敗パターンに絞って整理しました。
Prompt全文、raw output、失敗ログ、Research Artifact判定表、検証pipelineの設計案は、再現用の素材として別途まとめる予定です。
最後に、今回の検証の要点を一文で再掲します。
Web検索できることと、検証可能な調査成果物になることは別。












